索引是存储引擎用于快速找到记录的一种数据结构。尤其是当表的数据量越来越大的时候,正确的索引对查询性能的提升尤为明显。但在日常工作中,索引却常常被忽略,甚至被误解。本文将为大家简单介绍下Mysql索引优化的原理与注意事项。
一、索引的类型
1)B-Tree索引
B-Tree索引是用的最多的索引类型了,而且大多数存储引擎都支持B-Tree索引。
B-Tree本身是一种数据结构,其是为磁盘或其他直接存取的辅助设备而设计的一种平衡搜索树。Mysql中的B-Tree索引通常是B-Tree的变种B+Tree实现的。其结构如下:
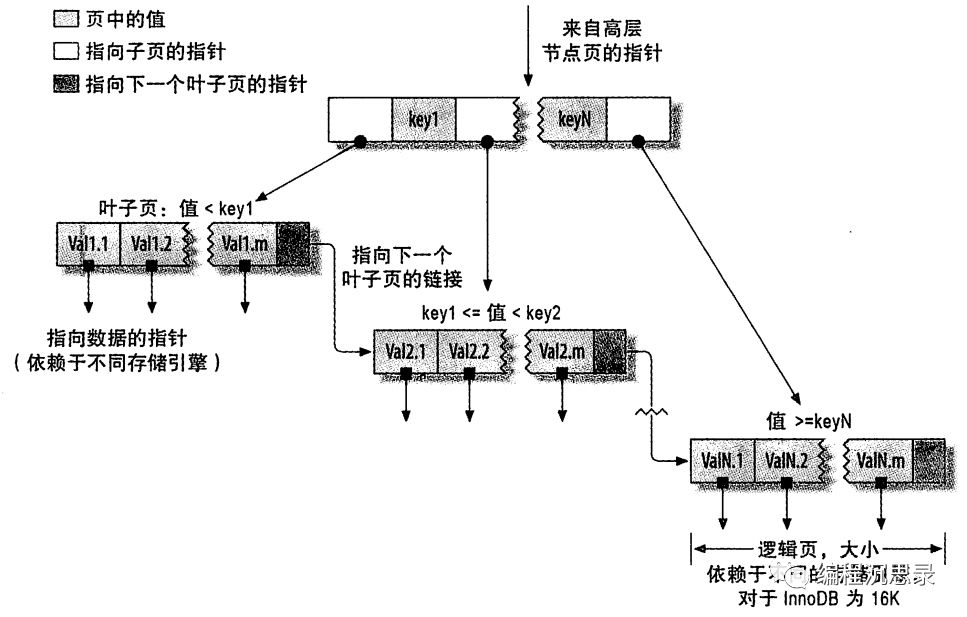
B+Tree的特点是,数据都存储在叶子节点,并且每个叶子节点的数据都是按相同顺序(升序或降序)排列存储的,再者相邻的叶子节点都用指针连接在一点,这种结构非常适合于范围查找。
B-Tree索引能够显著加快访问数据的速度,因为存储引擎不再需要进行全表扫描来获取需要的数据,而是从索引的根节点逐层往下进行搜索,这大大缩小了存储引擎扫描数据的范围,因此对查询速度的提升非常明显。
2)Hash索引
Hash索引,顾名思义,就是通过哈希表实现的索引。其特点是只有精确匹配索引的所有列才有效。对于每一行数据,存储引擎都会对所有索引列计算一个哈希码,Hash索引把哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
在Mysql中,目前只有Memory引擎显式支持Hash索引,而且由于Hash索引不支持范围查找,也不支持排序,更不支持部分索引列匹配查找,所以Hash索引用的比较少。
下文将着重介绍B-Tree索引的用法。
为了下文叙述方便,我们将假设有一个user表,其字段如下:
id:bigint类型,主键
name:varchar类型
age:int类型
interest:varchar类型
并且在name、age、interest上建立了一个联合索引index_1,索引顺序为(name,age,interest),这个索引顺序非常重要,后文将会提及。
二、B-Tree索引的用法
1)全值匹配
全值匹配指的是和索引中所有列进行匹配,如对上述user表查询 where name='aaa' and age=20 and interest='篮球' 是可以使用到索引的所有列的。
2)匹配最左前缀
匹配最左前缀是指只使用到多列索引的左边若干列。如对上述user表查询 where name = 'aaa' 是可以使用到索引的,并且只使用到索引的第一列。
3)匹配列前缀
匹配列前缀是指只匹配某一列的开头部分,如对上述user表查询 where name like 'aaa%' 是可以使用到索引的,注意是匹配列的开头部分,如果查询的是 where name like '%aaa'就不能使用到索引了。
4)匹配范围值
如对上述user表查询 where name > 'aaa' and name < 'bbb' 也是可以使用到索引的。
5)精确匹配某一列并范围匹配另外一列
如对上述user表查询 where name='aaa' and age >10,可以使用到索引,并且使用到索引的前2列。
三、B-Tree索引的限制
1)如果不是按照索引的最左列开始查找,则无法使用索引。
如对上述user表查询 where age=20则无法使用到索引,因为age不是索引列中的最左数据列。
2)不能跳过索引中的列。
如对上述user表查询 where name='aaa' and interest='足球',则只能使用到索引的第一列,因为where条件中没有包含age这一列。
总结
本文简要介绍了Mysql索引的原理及基本使用方法,关于Mysql索引还有不少知识点可以讲,由于篇幅所限,将在后续文章进行阐述。